
Contents: Introduction (Environment, Mobile Computers), The Model (Reading, Writing, Conflicts), Present & Future Work, Acknowledgements, Bibliography
Since some files (or jobs) are more important than others (to users) and since applications have different file access patterns, why should they all be forced to perform perhaps less than optimal due to the shortcommings of either optimistic or pessimistic replication? What if applications themselves could decide replication strategy and change it dynamically, e.g., due to change in quality or cost of communication or on demand if a user for some reason wishes to override default behaviour? In other words, what if applications could adapt their consistency requirements or demands according to the current state of the environment? The need for adaptation, whether on system or application level (or both), has already been recognized as an important [TACO] or even essential [CMU94183] capability of mobile clients (as members of a distributed system).
The work described in this position paper is part of the AMIGOS [AMIGOS] project. The subproject has been nicknamed PeStO for PEssimitic, STrict, and Optimistic, due to the fact that it---in contrast to the systems mentioned above---supports different levels of consistency (and availability). The overall goal is to support mobile computing by enabling applications at all times to adapt to their current environment.
socket interface. The types of mobile computers supported are discussed
in following Sections. The service provided is access to shared data
(files). The server can be considered as the true home of the shared files, and
the mobile clients as caching sites as in the traditional client/server model.
The server holds the primary copy or the first-class replica of
the file, and the clients cache second-class replicas.
In our environment, a mobile computer can be either connected to (the same network as) the server or disconnected. The connections can be by use of a variety of different technologies, such as Ethernet, dial-up telephone line, dial-up wireless communication, see Figure. Hence, the communication bandwidth may vary substantially as does the cost of using this bandwidth. Mobile clients that are connected via a fixed network, with high bandwidth and low latency (e.g., Ethernet) are said to be (fully) connected, whereas mobile clients that are connected via other means are weakly connected.
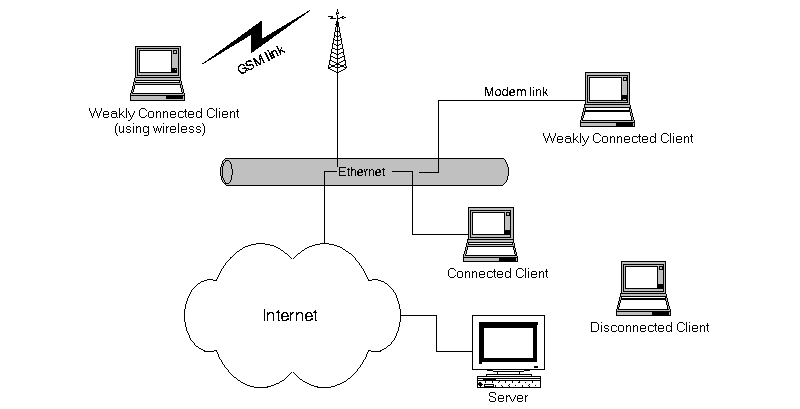
The mobile clients are in contact with the server on a regular basis, i.e., they do not stay disconnected forever and can be said to be permanent members of the distributed system in which the server resides. The server has no explicit support for stationary workstations, but of course, they can be considered as odd cases of mobile clients, that never move and always are fully connected.
sockets. In the long run it could be any
operating system providing a socket abstraction (in
C), so in this sense the mobile computers supported are
heterogeneous.
One obvious advantage of this choice is that it eliminates the need for caching
system files, as in Coda [Coda], Little
Work [LittleWork], and Seer [Seer]. This alleviates the
problem of predicting which system files that are actually needed, which is a
complicated matter. For example, in Coda [Coda] a special
spy program is used to track down use of files during a session and in
Seer [Seer] the problem is solved by constantly logging file references.
With every read (or any other non-mutating operation) must be
associated a Consistency Time Bound CTB, and with every write (or
any other mutating operation) a Modification Time Bound MTB. These can
either be given explicitly by the application or implicitly using some sort of
default value.
f, in the cache
with the associated values <MT_C=8.00,CT_i=9.00,CCT_i=9.00>. This would be the result
if the file was last updated on the server at 8.00, and cached by the client in
question at 9.00. At 10.00 (now) the client opens the file for reading:
open(f,"r",CTB)
If CTB>0 then f must be and remain consistent (with the server version)
within the specified
time bound. For example, with CTB=2 hours (from now), then f must be
guaranteed to be and remain consistent until 12.00.
In other words, f must not have been updated on the server between 9.00
(where it was cached) and 10.00 (now), and furthermore, it must not be updated
for the next 2 hours. If it has been updated between 9.00 and 10.00 then a new
copy of the file is required (for it to be consistent now). Under all circumstances
a read lock must be obtained (for it to remain consistent within the
time bound).
If obtaining a new copy of the file or a lock on the file (or both) succeeds then
the open succeeds, otherwise it fails. Using CTB>0 the client is
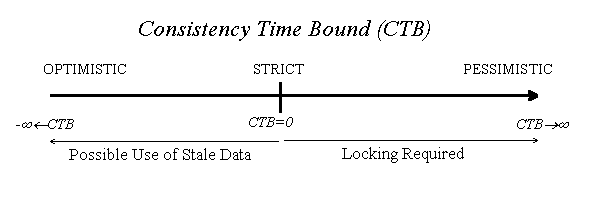
pessimistic. The greater CTB the more pessimistic.
If, on the other hand, CTB<0 then the client is satisfied with a file that was consistent sometime during the period lasting from minimum the time specified by the time bound (ago) and now. In the example above, with CTB=-2 hours (from now), the read succeeds because the file was consistent sometime within the last two hours, namely one hour ago (at 9.00). With CTB=1/2 hour, a new consistency check is required because the file cannot be guaranteed to be consistent half an hour ago (at 9.30). If the file has not been updated since 9.00 then the cached file can be used, otherwise a new copy of the file is required (in both cases CT_i and CCT_i can be updated to 10.00). Using CTB<0 the client is optimistic. The more negative the CTB the higher the level of optimism.
CTB=0 requires that the file is consistent now, but cannot be
guaranteed to remain consistent. By using this CTB the client is strict
in the sense that the file opened should be guaranteed to be consistent with the latest
update of the primary copy (at the time of the open). The correspondance
between the consistency time bound
and the level of pessimism or optimism is depicted in the Figure below.
The MTB associated with an open for writing is the ''mutating'' counterpart of the CTB associated with an open for reading:
open(f,"w",MTB).
A MTB<0 means that the writes (done locally) are delayed for a maximum of the specified time bound before written to the server. The delay increases the possibility of write-write conflicts, thus making the write operation increasingly optimistic the more negative the MTB.
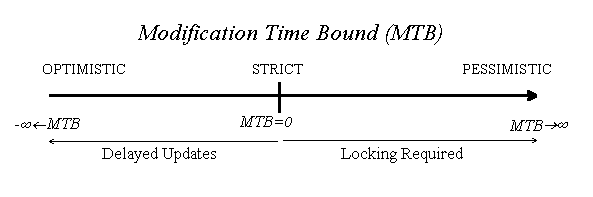
A write open with a MTB=0 assures that the update is propagated to the server as fast as possible, and a mtb>0 demands the file to be write locked, see Figure above. In both cases a connection to the server may have to be established (if it has not already been established or the file is already locked).
Let us consider a case of concurrent writing; assume for the sake of the argument that the order of operations are: P1 opens for writing, P2 opens for writing, P1 and P2 close for writing (in an undetermined order). The table below shows the possible conflicts.
| Write/write conflicts | ||||
| optimistic | strict | pessimistic | ||
| P2 writing | optimistic | FS,SF | FS,SF | P2 fails |
| strict | FS,SF | FS,SF | P2 fails | |
| pessimistic | P1 fails | P1 fails | P2 fails | |
Note: When P1 or P2 fails, it may not
result in write/write conflict, since the open rather
than the close might fail!
What is to be done about write/write conflicts? Some conflicts are more
serious than others, and some are easy to fix---but that is totally
application-specific, thus conflicts are best handled by applications.
How do we inform the applications of conflicts? Write/write
conflicts are detected after the file has been closed, either immediately
after or after a while, depending on the MTB. We choose to let the
close operation return SUCCESS (if no conflicts occur),
FAILURE (contraversely), or TIMEOUT.
If it takes some amount of time before the
updates are propagated to the server, then it is impossible to report
success or failure immediately. How long an application can wait for
the close to ''finish'' is also application-specific, so we will
let the applications decide. With each close should be associated
a close expiration time (CET>=0):
close(f,CET)
The close will not return until the updates are propagated
succesfully back to the server, or a conflict has been detected, or
it times out (according to the CET). With CET=0 the call will
return immediately, and with a very large CET the call returns only
when the status (success or failure) of the close has been
determined.
If the close fails or times out then the application can inform
the user, rename the cached file (using a special operation), re-execute the
commands, or do whatever steps it deems necessary!
At the time of writing the implementation had only just begun, thus we cannot report to you any results. We plan to have a full working implementation with test results no later than at the end of the year!
New (or ported) applications that utilize the new facilities need to be written and their performance weighted against the performance of existing applications before we are able to draw conclusions as to the viability of the model. Furthermore, it will be interesting to study the effects of applications or users operating on the same set of files using different levels of consistency.
Another matter also needs to be resolved; to what level are the applications expected to make their own decisions? Should the system ignore behaviour that seems irrational (e.g., using high degree of optimism, even though fully connected) under the assumption that applications know what they are doing, or should the system try to assist the applications as much as possible?
In the near future we hope to expand the model with a transactional facility, that enable applications or users to group operations into working units with the ''all-or-nothing'' property. Which decisions to make in order to provide an efficient and simple abstraction upon the proposed model for consistency remains (for now) nothing more than an interesting question. This will also make way for detection of read/write conflicts.
There are issues that we have not yet begun discussing but will have to deal with sooner or later. These issues include security (e.g., authentication and encryption), migration (mobility, i.e., crossing network and administration boundaries), and network optimisation (header compression, congestion control and avoidance). By basing our implementation on TACO, some of these issues are solved with the evolution of TACO.